|
Web Scraper [轻型爬虫]---简易教程03 |
|
一本时空
L0
• 2020-05-21 • 回复 1 • 只看楼主
• 举报
|
以后更新了,会补链接上去
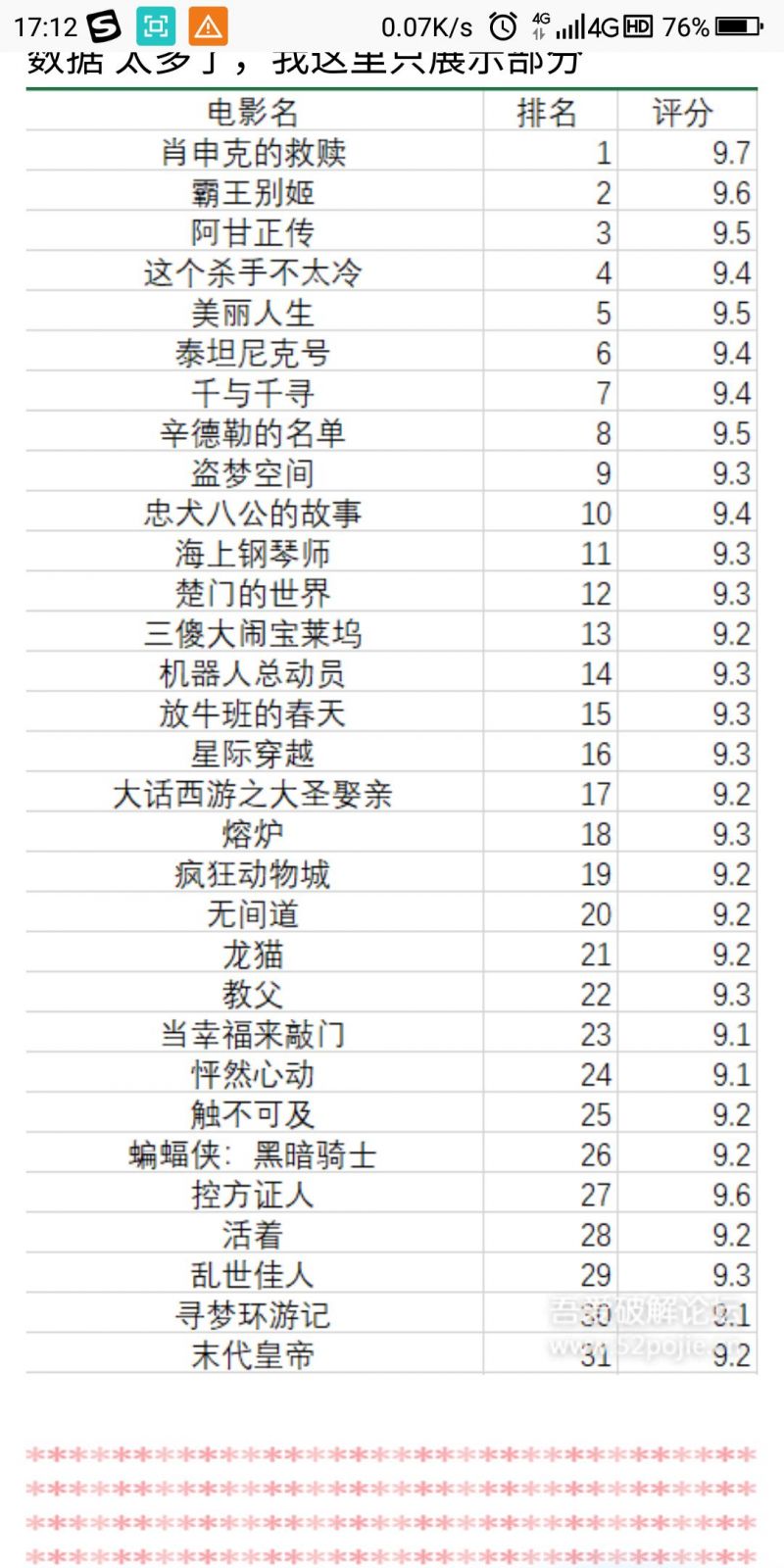
上期我们主要是实现了爬取多个元素,电影名,排名,评分。有的小伙伴会发现爬取的数据只是当前这
一页的数据,那么想要爬取后面的内容,应该怎么弄? 那么,这就是我们这次所要解决的问题!!
我在第一篇里面就说过,爬虫的本质就是网络请求和数据处理,然后在网页上面寻找规律
重点是规律 规律 规律 (重要的事情说三遍)
一般寻找规律首先从网址开始分析,因为一个好的程序员一般都会去用一定的规律去进行开发,不然他
离职了,后面的人想接手都没办法接,不好意思说偏了。
正式开始本次内容
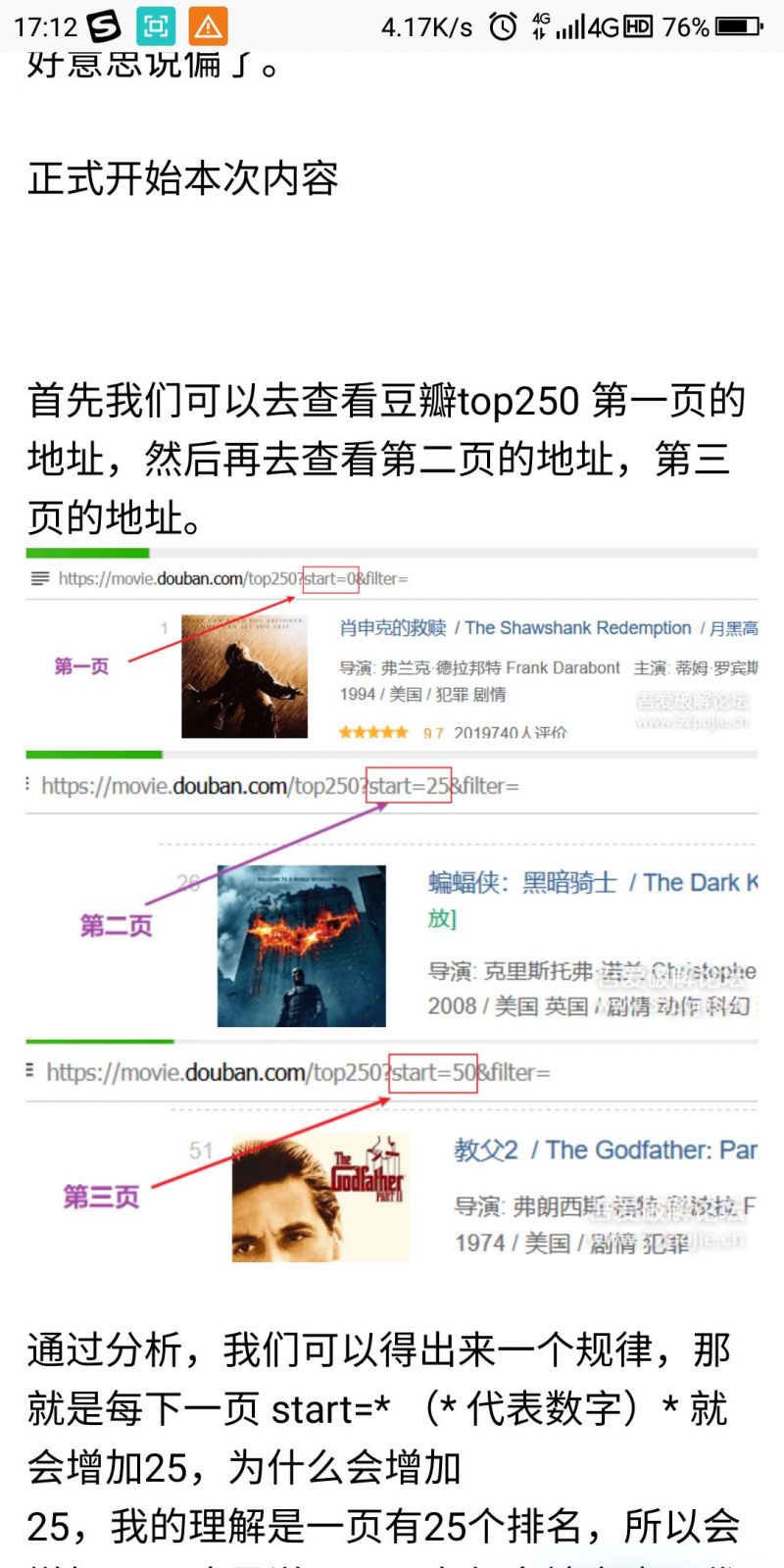
首先我们可以去查看豆瓣top250 第一页的地址,然后再去查看第二页的地址,第三页的地址。
通过分析,我们可以得出来一个规律,那就是每下一页 start=* (* 代表数字)* 就会增加25,为什么会增加
25,我的理解是一页有25个排名,所以会增加25,这里说一下 0 在很多地方也是代表一个排名,表示是第一
个。
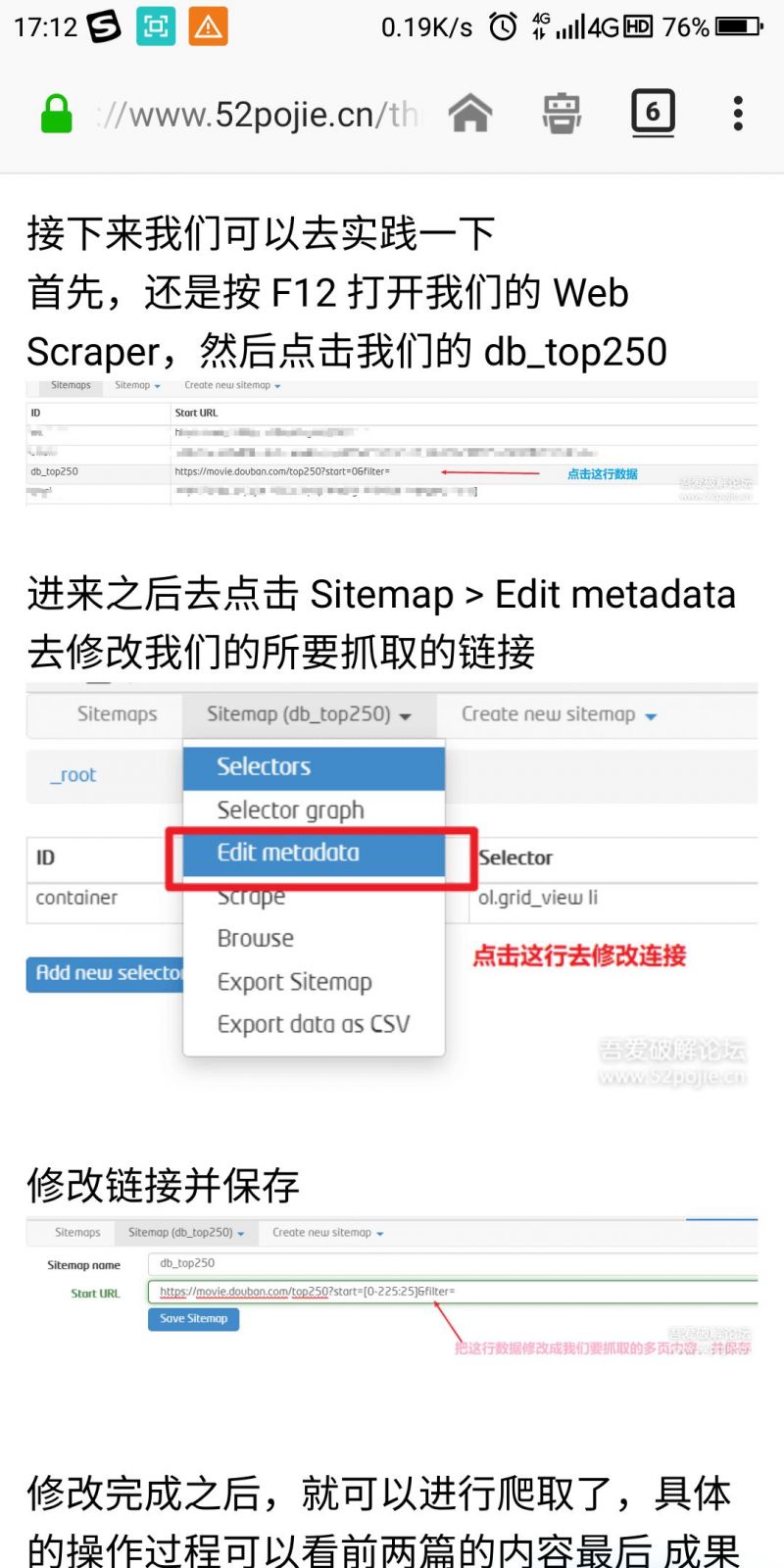
既然规律找到了,那这个问题就比较好解决了,Web Scraper 对这种分页链接是数字分页来获取网页的
提供了一个范围指定器。
例如:
我们想抓取4个网页 https://www..com/book/1

上期我们主要是实现了爬取多个元素,电影名,排名,评分。有的小伙伴会发现爬取的数据只是当前这
一页的数据,那么想要爬取后面的内容,应该怎么弄? 那么,这就是我们这次所要解决的问题!!
我在第一篇里面就说过,爬虫的本质就是网络请求和数据处理,然后在网页上面寻找规律
重点是规律 规律 规律 (重要的事情说三遍)
一般寻找规律首先从网址开始分析,因为一个好的程序员一般都会去用一定的规律去进行开发,不然他
离职了,后面的人想接手都没办法接,不好意思说偏了。
正式开始本次内容
首先我们可以去查看豆瓣top250 第一页的地址,然后再去查看第二页的地址,第三页的地址。
通过分析,我们可以得出来一个规律,那就是每下一页 start=* (* 代表数字)* 就会增加25,为什么会增加
25,我的理解是一页有25个排名,所以会增加25,这里说一下 0 在很多地方也是代表一个排名,表示是第一
个。
既然规律找到了,那这个问题就比较好解决了,Web Scraper 对这种分页链接是数字分页来获取网页的
提供了一个范围指定器。
例如:
我们想抓取4个网页 https://www..com/book/1