
|
Python 爬虫(一):爬虫伪装 |
|
旁观者
L21
• 2021-02-24 • 回复 0 • 只看楼主
• 举报
|
1 简介
对于一些有一定规模或盈利性质比较强的网站,几乎都会做一些防爬措施,防爬措施一般来说有两种:一种是做身份验证,直接把虫子挡在了门口,另一种是在网站设置各种反爬机制,让虫子知难而返。
2 伪装策略
我们知道即使是一些规模很小的网站通常也会对来访者的身份做一下检查,如验证请求 Headers,而对于那些上了一定规模的网站就更不用说了。因此,为了让我们的爬虫能够成功爬取所需数据信息,我们需要让爬虫进行伪装,简单来说就是让爬虫的行为变得像普通用户访问一样。
2.1 Request Headers 问题
为了演示我使用百度搜索 163 邮箱

使用 F12 工具看一下请求信息
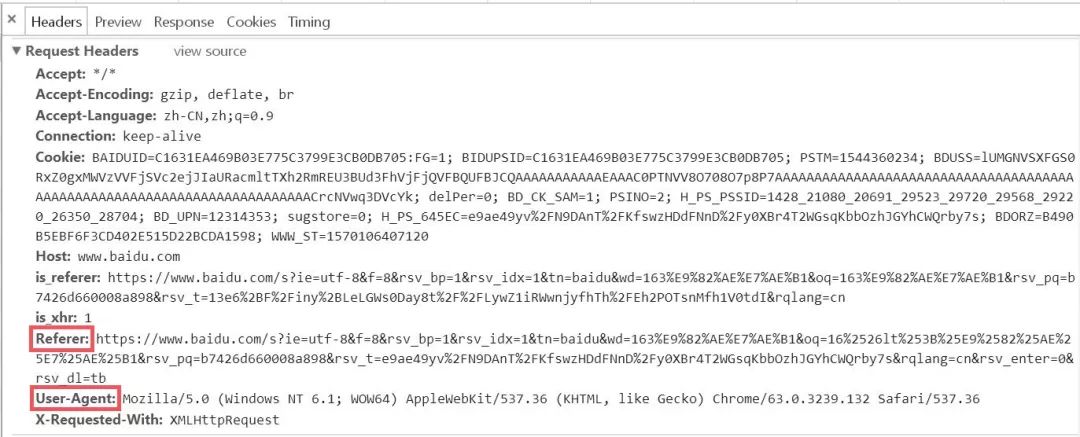
在上图中,我们可以看到 Request Headers 中包含 Referer 和 User-Agent 两个属性信息,Referer 的作用是告诉服务器该网页是从哪个页面链接过来的,User-Agent 中文是用户代理,它是一个特殊字符串头,作用是让服务器能够识别用户使用的操作系统、CPU 类型、浏览器等信息。通常的处理策略是:1)对于要检查 Referer 的网站就加上;2)对于每个 request 都添加 User-Agent。
2.2 IP 限制问题
有时我们可能会对一些网站进行长期或大规模的爬取,而我们在爬取时基本不会变换 IP,有的网站可能会监控一个 IP 的访问频率和次数,一但超过这个阈值,就可能认作是爬虫,从而对其进行了屏蔽,对于这种情况,我们要采取间歇性访问的策略。
通常我们爬取是不会变换 IP 的,但有时可能会有一些特殊情况,要长时间不间断对某网站进行爬取,这时我们就可能需要采用 IP 代理的方式,但这种方式一般会增加我们开销,也就是可能要多花钱。
3 总结
有些时候我们进行爬取时 Request Headers 什么的已经做好了伪装,却并未得到如愿以偿的结果,可能会出现如下几种情况:得到的信息不完整、得到不相关的信息、得不到信息,这种情况我们就需要研究网站的防爬机制,对其进行详细分析了。常见的几种我列一下:
1)不规则信息:网址上会有一些没有规则的一长串信息,这种情况通常采用 selenium(模拟浏览器,效率会低一些) 解决;
2)动态校验码:比如根据时间及一些其他自定义规则生成,这种情况我们就需要找到其规则进行破解了;
3)动态交互:需要与页面进行交互才能通过验证,可以采用 selenium 解决;
4)分批次异步加载:这种情况获取的信息可能不完整,可以采用 selenium 解决。
