
|
《民国奇探》的弹幕有点逗比,用 Python 爬下来看看 |
|
旁观者
L21
• 2021-03-01 • 回复 0 • 只看楼主
• 举报
|

电视剧《民国奇探》是一部充斥着逗比风的探案剧,剧中主要角色:三土、四爷、白小姐,三土这个角色类似于《名侦探柯南》中的柯南但带有搞笑属性,四爷则类似于毛利小五郎但有大哥范且武功高强,三土尚文四爷尚武,白小姐大多时候扮演着傻白甜的角色。
因为该剧目前大多数时候都处于爱奇艺电视剧的榜首位置,所以自己也看了几集,总的来说剧情紧凑,剧风逗比,当然最令我印象深刻的还是网友们逗比的弹幕,所以我决定用 Python 将弹幕爬下来大家一起瞧瞧。
数据爬取
现在开始我们的爬取工作,先用浏览器打开电视剧的网页,地址为:https://www.iqiyi.com/v_19rx2un304.html?vfrm=pcw_home&vfrmblk=B&vfrmrst=fcs_0_t12,我们使用开发者工具的 Network 功能,进到 Network 控制台后,我们先使用 Ctrl+R 命令重新加载一下网页,然后再通过过滤器搜索 bullet,如下图所示: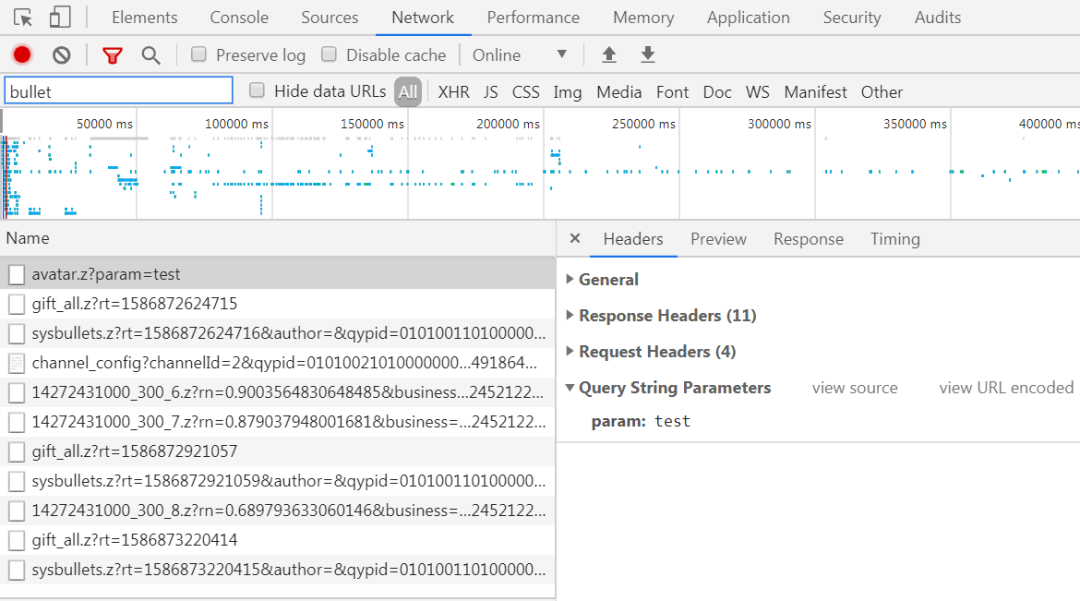
这里的弹幕数据是以 .z 形式的压缩文件存在的,如下图所示: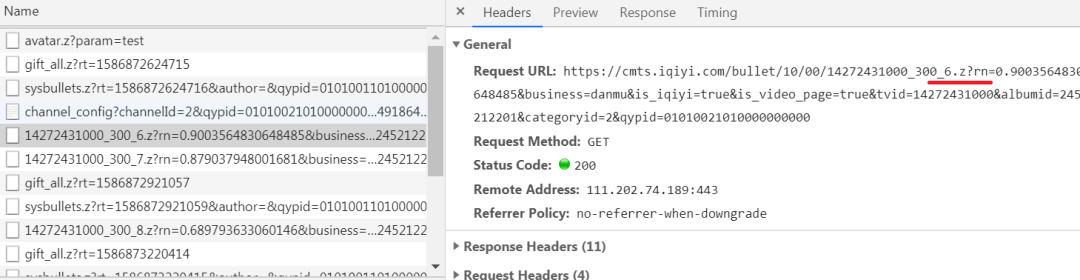
我们可以看出压缩文件命名规则为 tvid_300_n.z,所以我们先来获取 tvid 列表,代码实现如下所示:
def get_tvid():
# tv_id 列表
tv_id_list = []
for i in range(1, 5):
url = 'https://pcw-api.iqiyi.com/albums/album/avlistinfo?' \
'aid=245212201&page='\
+ str(i) + '&size=30'
res = requests.get(url).text
res_json = json.loads(res)
# 视频列表
move_list = res_json['data']['epsodelist']
for j in move_list:
tv_id_list.append(j['tvId'])
return tv_id_list获取到 tvid 列表后,我们就可以根据 tvid 获取弹幕的压缩文件了,然后再对其进行解压及存储,实现代码如下所示:
def save_bullet(tvid):
for page in range(1, 10):
url = 'https://cmts.iqiyi.com/bullet/'\
+ tvid[-4:-2] + '/'\
+ tvid[-2:] + '/'\
+ tvid + '_300_'\
+ str(page) + '.z'
print(url)
# 请求弹幕压缩文件
res = requests.get(url).content
res_byte = bytearray(res)
try:
xml = zlib.decompress(res_byte).decode('utf-8')
# 保存路径
path = 'data/' + tvid + '_300_' + str(page) + '.xml'
with open(path, 'w', encoding='utf-8') as f:
f.write(xml)
except:
return文件存储到本地之后,我们先获取每一个文件的全路径名,实现代码如下所示:
def get_file(path):
for root, ds, fs in os.walk(path):
for f in fs:
yield root + '/' + f获取到所有文件全路径名后,我们再根据全路径名获取文件并解析弹幕文本信息,实现代码如下所示:
def get_bullet_text(f):
DOMTree = parse(f)
collection = DOMTree.documentElement
# 评论文本内容
xml_list = collection.getElementsByTagName('content')
content_list = []
for j in xml_list:
content_list.append(j.childNodes[0].data)
return content_list最后,我们可以将整个弹幕字符串信息保存起来,因为我本次爬取的弹幕信息并不是特别多,所有就先存到 txt 文件中吧,实现代码如下所示:
def save2txt(content):
with open('bullet.txt', 'a', encoding='utf-8') as file:
file.write(content)词云展示
数据保存完了之后,我们再来个词云展示吧,代码实现如下所示:
def jieba_():
content = open('bullet.txt', 'rb').read()
# jieba 分词
word_list = jieba.cut(content)
words = []
# 过滤掉的词
remove_words = ['还是', '不会', '一些', '所以', '果然',
'起来', '东西', '为什么', '真的', '这么',
'但是', '怎么', '还是', '时候', '一个',
'什么', '自己', '一切', '样子', '一样',
'没有', '不是', '一种', '这个', '为了']
for word in word_list:
if word not in remove_words:
words.append(word)
global word_cloud
# 用逗号隔开词语
word_cloud = ','.join(words)
def cloud():
# 打开词云背景图
cloud_mask = np.array(Image.open('bg.png'))
# 定义词云的一些属性
wc = WordCloud(
# 背景图分割颜色为白色
background_color='white',
# 背景图样
mask=cloud_mask,
# 显示最大词数
max_words=300,
# 显示中文
font_path='./fonts/simhei.ttf',
# 最大尺寸
max_font_size=70
)
global word_cloud
# 词云函数
x = wc.generate(word_cloud)
# 生成词云图片
image = x.to_image()
# 展示词云图片
image.show()
# 保存词云图片
wc.to_file('mgqt.png')看一下效果:

源码:蓝奏云链接
