
|
我爬取了知乎上大学相关话题中的热门高赞问答,其中是否有你大学生活的影子呢? |
|
旁观者
L21
• 2021-03-01 • 回复 0 • 只看楼主
• 举报
|
你的大学生活过得怎么样?充实?有趣?有遗憾?本文我们使用 Python 爬取知乎上大学相关话题中的热门高赞问答,看看是否有你熟悉的场景。
爬取
首先,我们到知乎上搜一些大学相关话题中热度比较高的几个,如下图所示:
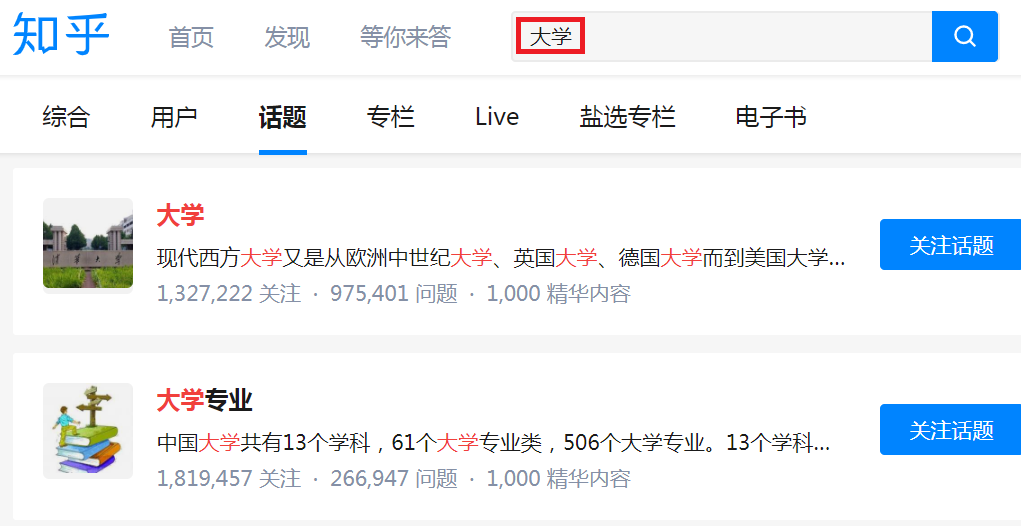
这个我们通过话题的关注人数、问题数量、精华内容等方面判断,接着我们用鼠标选中一个话题点进去,如下图所示:
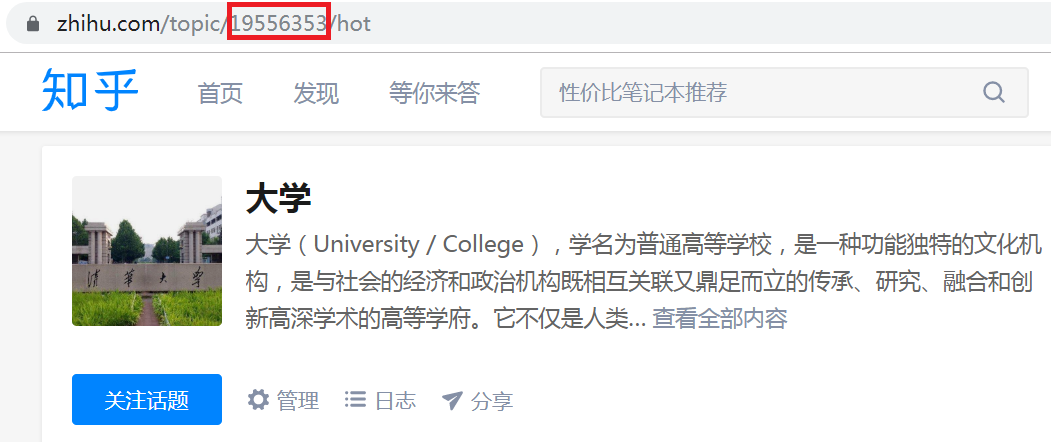
我们要记录一下网址中的话题 ID,就是网址中 topic 后面那一串数字,这个在爬取时要用到。
接下来我们看一下爬取的实现,我们先导入需要用到的 Python 库,如下所示:
import re, json, random, requests, urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)爬取问答内容的具体实现代码如下所示:
def get_answers_by_page(topic_id, page_no):
global db, answer_ids, maxnum
limit = 10
offset = page_no * limit
url = "https://www.zhihu.com/api/v4/topics/" + str(
topic_id) + "/feeds/essence?include=data%5B%3F(target.type%3Dtopic_sticky_module)%5D.target.data%5B%3F(target.type%3Danswer)%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F(target.type%3Dtopic_sticky_module)%5D.target.data%5B%3F(target.type%3Danswer)%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F(type%3Dbest_answerer)%5D.topics%3Bdata%5B%3F(target.type%3Dtopic_sticky_module)%5D.target.data%5B%3F(target.type%3Darticle)%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F(type%3Dbest_answerer)%5D.topics%3Bdata%5B%3F(target.type%3Dtopic_sticky_module)%5D.target.data%5B%3F(target.type%3Dpeople)%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics%3Bdata%5B%3F(target.type%3Danswer)%5D.target.annotation_detail%2Ccontent%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F(target.type%3Danswer)%5D.target.author.badge%5B%3F(type%3Dbest_answerer)%5D.topics%3Bdata%5B%3F(target.type%3Darticle)%5D.target.annotation_detail%2Ccontent%2Cauthor.badge%5B%3F(type%3Dbest_answerer)%5D.topics%3Bdata%5B%3F(target.type%3Dquestion)%5D.target.annotation_detail%2Ccomment_count&limit=" + str(
limit) + "&offset=" + str(offset)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
}
try:
r = requests.get(url, verify=False, headers=headers)
except requests.exceptions.ConnectionError:
return False
content = r.content.decode("utf-8")
data = json.loads(content)
is_end = data["paging"]["is_end"]
items = data["data"]
if len(items) <= 0:
return True
pre = re.compile(">(.*?)<")
for item in items:
if maxnum <= 0:
return True
answer_id = item["target"]["id"]
if answer_id in answer_ids:
continue
if item["target"]["type"] != "answer":
continue
if int(item["target"]["voteup_count"]) < 10000:
continue
answer = ''.join(pre.findall(item["target"]["content"].replace("\n", "").replace( " " , "")))
if len(answer) == 0:
continue
if len(answer) > 200:
continue
answer_ids.append(answer_id)
question = item["target"]["question"]["title"].replace("\n", "")
vote_num = item["target"]["voteup_count"]
if answer.find("<") > -1 and answer.find(">") > -1:
pass
sline = "=" * 50
content = sline + "\nQ: {}\nA: {}\nvote: {}\n".format(question, answer, vote_num)
print(content)
save2file(content)
maxnum -= 1
return is_end爬取方法中的两个参数分别表示话题 ID 以及爬取的内容是第几页。
我们可以将爬取的内容保存到文件中,实现代码如下:
def save2file(content):
with open('result', 'a', encoding='utf-8') as file:
file.write(content)源码:蓝奏云链接
