
|
8个 Python 小技巧 |
|
旁观者
L21
• 2021-07-08 • 回复 0 • 只看楼主
• 举报
|
Python 可以说是数据科学生态系统中最流行的编程语言。受欢迎的原因之一是为数据科学选择了丰富的数据处理方法。
在本文中,我将分享8个非常棒的方法、函数,它们在你的日常工作中派上用场。
我们开始吧!
1、hasnans
有许多方法可以检查 Series/DataFrame 是否包含缺少的值,包括 missingno 之类的专用库。检查 DataFrame 的列是否包含缺少的值的简单方法如下所示:
df["column"].isna().any()
或者,我们可以使用 pd.Series 的 hasnans 方法来稍微减少键入:
df["column"].hasnans
一个缺点是这种方法不适用于数据帧,尽管我们可以很容易地将其与列表理解结合使用:
[df[col].hasnans for col in df.columns]
很自然,使用这种方法会丢失列的名称。所以我想说 hasnans 的主要用例是对单个列进行快速检查。
2、transform
transform 方法用于对整个数据帧应用转换,或对选定列应用不同的转换。然而,使这个方法脱颖而出的是,它返回一个与输入形状相同的对象。
这就是为什么在处理聚合时转换可以节省大量时间的原因。通常,如果我们希望在原始数据帧中有一些聚合值,我们将使用 groupby 创建一个新的、更小的数据帧,然后将其合并回原始数据帧。这有点费时,会产生不必要的中间对象。
有了 transform ,我们可以一次性完成!让我们创建一个数据框,其中包含一些店铺ID和它们在多天内的销售额(为简单起见,我们跳过日期)。
df = pd.DataFrame(data={"shop_id": [1, 1, 1, 2, 2, 2, 3, 3],"sales": [10, 40, 50, 20, 20, 40, 20, 50]})
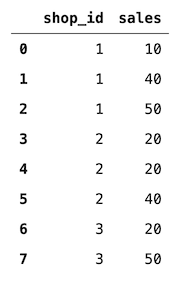
我们可以使用以下代码片段轻松地添加每家商店的销售额总和:
df["total_sales_per_shop"] = df.groupby("shop_id")["sales"].transform("sum")
df
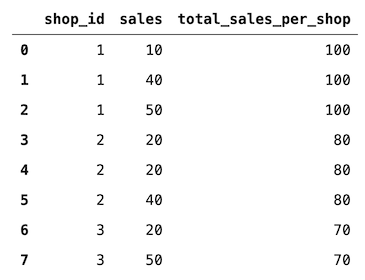
transform 无疑简化了过程。一个更高级的 transform 用例可以用于聚合过滤。例如,我们要提取有关销售超过75个商品单位的商店的行。理想情况下,无需在输出数据帧中创建新列。我们可以这样做:
df = pd.DataFrame(data={"shop_id": [1, 1, 1, 2, 2, 2, 3, 3],"sales": [10, 40, 50, 20, 20, 40, 20, 50]})
df.loc[df.groupby("shop_id")["sales"].transform("sum") > 75]
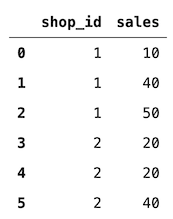
3、merge_asof
原则上,这个函数类似于标准的左连接,但是,我们匹配最近的键而不是相等的键。通过一个例子,这一点会变得更清楚。
我们还需要知道,使用 merge_asof 连接有3个方向:
-
backward:对于左数据帧中的每一行,我们选择右数据帧中on键小于或等于左键的最后一行。这是默认值。
-
forward:对于左数据帧中的每一行,我们选择右数据帧中的第一行,其on键大于或等于左数据帧的键。
-
nearest:对于左数据帧中的每一行,我们搜索选择右数据帧中的行,其on键在绝对距离上最接近左键。
另一件需要考虑的事情是,两个数据帧都必须按键排序。
在这里,我们有两个数据帧,一个包含交易信息,另一个包含报价。两者都包含详细的时间戳。
trades = pd.DataFrame(
{
"time": [
pd.Timestamp("2016-05-25 13:30:00.023"),
pd.Timestamp("2016-05-25 13:30:00.038"),
pd.Timestamp("2016-05-25 13:30:00.048"),
pd.Timestamp("2016-05-25 13:30:00.048"),
pd.Timestamp("2016-05-25 13:30:00.048")
],
"ticker": ["MSFT", "MSFT", "GOOG", "GOOG", "AAPL"],
"price": [51.95, 51.95, 720.77, 720.92, 98.0],
"quantity": [75, 155, 100, 100, 100]
}
)
quotes = pd.DataFrame(
{
"time": [
pd.Timestamp("2016-05-25 13:30:00.023"),
pd.Timestamp("2016-05-25 13:30:00.023"),
pd.Timestamp("2016-05-25 13:30:00.030"),
pd.Timestamp("2016-05-25 13:30:00.041"),
pd.Timestamp("2016-05-25 13:30:00.048"),
pd.Timestamp("2016-05-25 13:30:00.049"),
pd.Timestamp("2016-05-25 13:30:00.072"),
pd.Timestamp("2016-05-25 13:30:00.075")
],
"ticker": [
"GOOG",
"MSFT",
"MSFT",
"MSFT",
"GOOG",
"AAPL",
"GOOG",
"MSFT"
],
"bid": [720.50, 51.95, 51.97, 51.99, 720.50, 97.99, 720.50, 52.01],
"ask": [720.93, 51.96, 51.98, 52.00, 720.93, 98.01, 720.88, 52.03]
}
)
然后,我们在报价时间和交易时间之间的2ms内合并两个数据帧:
df = pd.merge_asof(trades, quotes, on="time", by="ticker", tolerance=pd.Timedelta("2ms"))
df
结果如下:
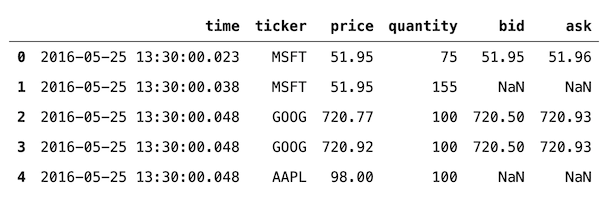
通过从输出帧到两个数据帧的后续示例,最容易理解合并的逻辑。
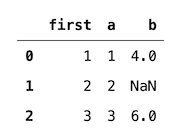
4、insert
这是一个简单,但方便的方法。我们可以使用它将列插入数据帧中的特定位置。
最常见的用例是当我们想添加一个包含额外信息的列以便于分析输出时。为了我们和利益相关者的方便,这些信息作为第一栏最有用。我们可以使用以下代码段来执行此操作:
df = pd.DataFrame(data={"a": [1, 2, 3],"b": [4, np.nan, 6]})
df.insert(0, "first", [1, 2, 3])
df
5、explode
当我们要将数据帧中的列表展开为多行时,explode 很有用。想象一下:我们有两个 ID 和多个值存储在每个ID的列表中。我们希望每个 ID 值组合有一行。
df = pd.DataFrame(data={"id": [1, 2], "values": [[1, 2, 3], [4, 5, 6]]})
df

df.explode("values", ignore_index=True)

6、str
在处理包含字符串的列时,我们可以使用 str,它允许我们使用各种方便的方法,这些方法可以以矢量化的方式应用于整个列。
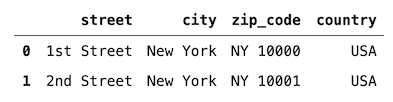
例如,我们可以轻松地将包含完整地址的列拆分为单独的组件。首先,让我们创建数据帧。
df = pd.DataFrame(data={"address": ["1st Street, New York, NY 10000, USA", "2nd Street, New York, NY 10001, USA"]
})
df

然后,我们可以使用 str.split 方法来创建新的列。
df = df["address"].str.split(",", expand=True)
df.columns = ["street", "city", "zip_code", "country"]
df
另一种可能性是使用 str.replace 方法修改字符串。
7、read_clipboard
当你经常使用 Excel/Google 工作表或接收此类文件中的数据时,此功能尤其有用。
使用 read_clipboard,我们可以轻松地将数据从源工作表加载到 Pandas 使用我们的计算机的剪贴板。这样,我们就不需要将文件保存到.csv或.xls。当然,这对于一些小型的特殊分析非常有用。

在上面,您可以看到 googlesheets 中的一个简单表格示例。我们选择范围,按cmd+c(或Windows的control+c),然后使用下面的代码段轻松地将数据加载到Python中:
pd.read_clipboard()

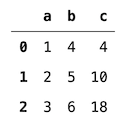
8、eval
eval 方法使用字符串表达式有效地计算数据帧上的操作。
df = pd.DataFrame(data={"a": [1, 2, 3],"b": [4, 5, 6]})
df = df.eval("c = a * b")
df
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

声明:本文系转载文章,仅供学习交流使用,侵权请联系删除
