
|
Linux篇--高频常用命令grep、awk、sed |
|
旁观者
L21
• 2021-05-17 • 回复 1 • 最后编辑于2021-05-17 22:19 • 只看楼主
• 举报
|
一、检索内容(grep)
我们先准备两个文件:
[root@192 mnt]# cat hehe1.txt
hello world
hello hadoop
hello hive
[root@192 mnt]# cat hehe2.txt
I love you!
Hello world.
查询带有ve的内容:

管道操作符|:多个指令连接起来,前一个指令的结果作为下一个指令的输入

grep -v:是反向查找的意思,比如 grep -v "grep" 就是查找不含有 grep 字段的行
二、内容处理(awk)
我们先准备个文件:
[root@192 mnt]# cat emp.txt
empno enname job mgr hiredate sal comm deptno
7369 刘一 职员 7902 1980-12-17 800 null 20
7499 陈二 推销员 7698 1981-02-20 1600 300 30
7521 张三 推销员 7698 1981-02-22 1250 500 30
7566 李四 经理 7839 1981-04-02 2975 null 20
7654 王五 推销员 7698 1981-09-28 1250 1400 30
7698 赵六 经理 7839 1981-05-01 2850 null 30
7782 孙七 经理 7839 1981-06-09 2450 null 10
7788 周八 分析师 7566 1987-06-13 3000 null 20
7839 吴九 总裁 null 1981-11-17 5000 null 10
7844 郑十 推销员 7698 1981-09-08 1500 0 30
7876 郭十一 职员 7788 1987-06-13 1100 null 20
7900 钱多多 职员 7698 1981-12-03 950 null 30
7902 大锦鲤 分析师 7566 1981-12-03 3000 null 20
7934 木有钱 职员 7782 1983-01-23 1300 null 10
我们只要第一和第二列:
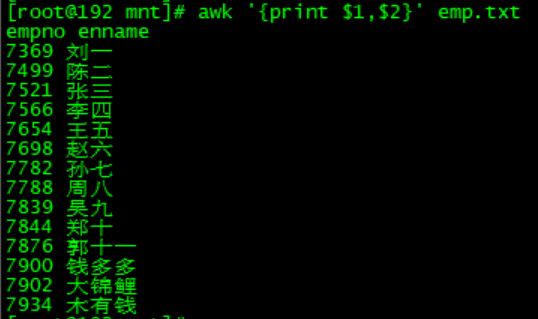
注:第0列其实就是完整,awk '{print $0}' emp.txt命令会将所有内容都打印出来。
我们只要第一列员工编号为7654的行:

你还想要第一行头的话:

如果文件中把分隔符由默认制表符改为逗号的话需要加-F:awk -F "," '{print $1}' emp.txt
三、内容替换(sed)
替换hehe1.txt文件中的hadoop替换为spark(文件中的真实内容并没有被替换掉,只是输出的结果被替换掉了):

如果想让替换在文件中生效需要加-i参数:

如果要替换特殊字符如;需要加转义字符\:sed -i 's/\;//' hehe1.txt
想要把e换成E(但是发现并没有把所有的e都替换了):sed -i 's/e/E/' hehe1.txt
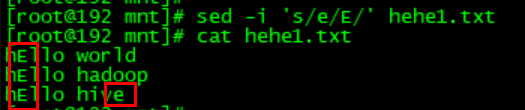
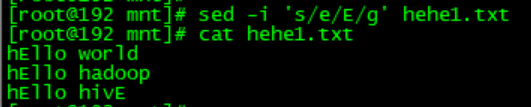
默认是只替换一个,如果想要全局替换的话后面需要加一个g:
声明:本文系转载文章,仅供学习交流使用,侵权请联系删除
